
「画像生成の仕組みを初心者向けに解説して欲しい」「おすすめ画像生成AIサービスって何がある?」といった悩みを抱いている人も多いでしょう。
本記事ではAI初心者の人でも分かるように専門用語をできるだけ省き、具体例を入れて「画像生成AI」について解説しています。
本記事で分かる内容は以下の通りです。
- そもそも画像生成AIとは何を意味しているのか
- そのほかの生成AIについて
- 画像生成AIで画像が作れる仕組み
- おすすめの画像生成AIサービス
画像生成AIとはテキストから画像を生成する技術
画像生成AIとは、テキストを入力するだけで簡単に画像を作れる技術です。
ここ最近はLINEの「AIイラストくん」をはじめ簡単に利用できるようになったため、一度は見たことがある人も多いでしょう。
ここまで画像生成AIがブームになったのは「Midjourney」と「Stable Diffusion」の2つが2022年の夏にリリースされたことが要因として挙げられます。
では画像生成AIでどんな画像が作れるのでしょうか。以下の画像はStable Diffusionにて「Mt.Fuji」と入力して生成された画像です。
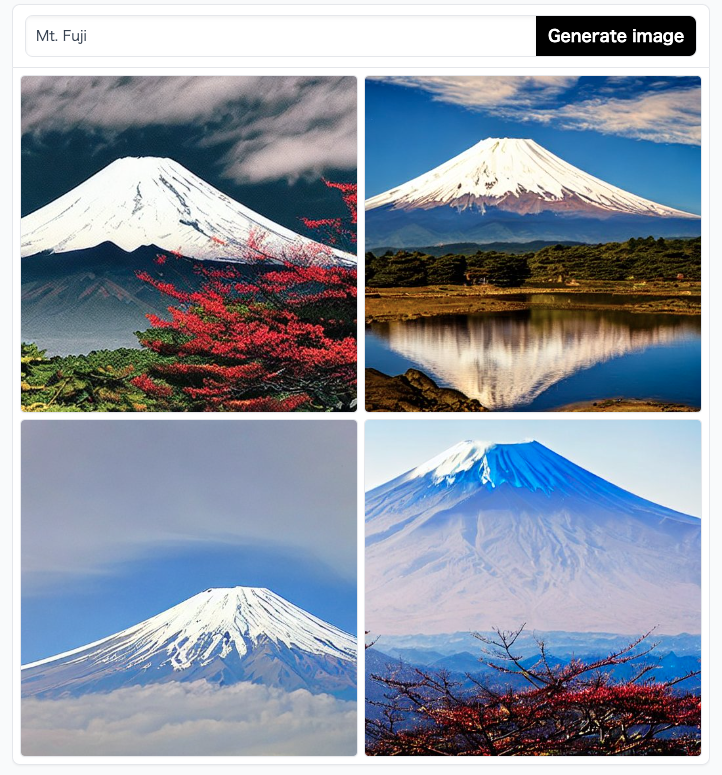
この画像は入力された文章(プロンプト)で新たに生成された画像であり、ネット上などから拾ってきているわけではありません。
プロンプトは「日本語対応していない場合」や「日本語で入力すると精度が落ちる場合」も多いため、現状多くのサービスにおいて英語で入力することが推奨されています。
そもそも生成AIとは
画像”生成AI”と呼ばれることから分かるように、他にも生成AIは存在しています。生成AIの具体例は以下の通りです。
- テキスト生成AI:ChatGPT
- 動画生成AI:Runway Gen-2
- 音声生成AI:Voicevox
生成AI(ジェネレーティブAI)とはAIを用いて文章や画像、動画などを生み出す種類のAIに分類されます。
例えば、RunwayのGen-2はテキストを入力すると動画が生成される「text to video」です。
一方で、同じくRunwayから出ているGen-1は既存の動画から新たな動画を生成する「video to video」となっています。
つまり「生成AI = 文章で生み出す」というわけではなく、入力するものはテキスト以外にも画像や動画なども存在しているわけです。
AIには生成AIの他にも「Amazonのレコメンド機能」など特定の何かを作るためではなく、別の目的で利用される種類もあります。
画像生成AIは結局何ができるのか
冒頭でも解説したように、画像生成AIはプロンプトを入力することによって作成したい画像を自動で生成できる技術です。
実際に画像生成AIが活用できる状況は、以下のような例が挙げられます。
- プレゼン資料やWebサイト内で使うとき
- 現実では起こり得ない状況の画像を作るとき
- 広告のモデルに使う人間をAIで代替するとき
生成できる画像は現実に存在する「富士山」のようなものだけではなく、現実ではありえない風景や動物も作れます。
例えばStable Diffusionで「屋根にいるトラ」と英語で入力してみましょう。

本来撮影するのが不可能な画像でも、画像生成AIを使うことによって再現できてしまうわけです。
また、現時点で企業が画像生成AIを活用している例も少なくありません。
例えば、某有名な美容外科クリニックでは、広告で登場する女性を画像生成AIで作成しています。有識者であれば「画像生成AIで作った人間だな」と判断できますが、多くの人は違和感なく「人間の女性」として認識するほどクオリティが高いのです。
つまり画像生成AIを利用することによって、これまで必要経費であった「モデルの利用料」が不要となり、ほとんど費用をかけることなく広告塔が用意できるようになります。
ただ、これは画像生成AIの技術を活用したほんの一例に過ぎません。
最終的にはあらゆる画像がAIに代替される可能性も
現時点では広告のモデルや、プレゼンで使う素材などで画像生成AIを利用している例が多く、あくまで「費用や手間を減らす」といったそこまで爆発力あるとは言えない利用法がほとんどです。
ただ、今後はあらゆる静止画がAIで作れるようになる可能性が高いため、画像生成AIを活用したビジネスもさまざま出てくるでしょう。
例えば、画像生成AIを用いた漫画を生成して、出版することも現実的に可能です。「漫画風に書いて」とプロンプトで入力すれば、現時点でも漫画っぽい画像は生成できます。これが進化すれば、ストーリーから漫画に落とし込むまですべてAIで完結することも夢ではありません。
今後も「画像生成AIがどのように活用されていくのか」は注目すべきトピックです。
画像生成AIで画像が作れる仕組みは学習によって成り立っている
ここまでの内容で、画像生成AIの基本的な内容や「できること」は理解できたと思います。ただ、実際にどのような仕組みで画像生成AIから画像が作られているのかはまだよく分からない人も多いですよね。
画像生成AIは「学習」という仕組みによって成り立っています。コンピュータに何千枚〜何億枚もの画像を学習させ、その学習データから画像を生成しているのです。ただ、この仕組みだけだと、学習したデータの中からテキストに合った画像を探してくるだけの機能になってしまいます。
そこで画像データに適度なノイズを加えることによって、これまで学習してきた画像にはない新たな画像が生成できるようになるわけです。ノイズは〔0.1,0.4,0.5…]のようなランダムな数値のリストで、これをAIに与えることでさまざまな種類の画像が生成できます。
プロンプトを全く同じにしても同じ画像ができないのは、この「ノイズ」も影響しているわけです。ランダムな数値リストが同じであれば同じ画像が生成されますが、現実的にノイズが同じになる可能性は極めて低く、同じプロンプトで同じ画像が生成されることはまずありません。
画像生成AIが生成される仕組みは大きく3ステップ
では、画像生成AIによって画像が作られる仕組みはどのようなものなのか。大きく分けて以下の3つのステップに分類されます。
- テキストを入力
- テキストエンコーダがテキストをベクトル化
- ベクトルを元に画像生成器が画像を生成
画像生成AIではテキストをそのままテキストとして受け取っているわけではなく、AIが理解できるように「ベクトル」に変換して内容を理解しています。ベクトルとは簡単に言うと、機械が内容を理解するために「テキストを数字に変換したもの」だと認識しておいてください。
例えば、画像生成AIのプロンプトとして「犬」と入力した場合、「犬」という単語を[0.1.0.4,0.8]のように数値へ変換します。具体的にプロンプトがどのような数値リストになるかは利用するAIツールによって異なるため、この数値リストはあくまで参考例です。
そして画像生成器は、このベクトルを画像に変換する役割を担っています。
実際には内部で複雑な技術が用いられていますが、まずは大まかな流れを理解しておきましょう。
画像生成AIに用いられる手法は6つ
画像生成AIに用いられる手法は主に6つです。
少し専門的な内容になるため「そこまで詳しく理解しなくても良い」という人は飛ばしていただいてかまいません。
- GAN(敵対的ネットワーク)
- VAE(変分オートエンコーダ)
- Pix2Pix
- TransGAN
- DALL-E
- StyleGAN/StyleGAN2
それぞれ解説していきます。
GAN(敵対的生成ネットワーク)
GAN(敵対的生成ネットワーク)はAIが新たに画像を生成する手法です。
まずは「生成器」が新しく画像を生成し、その画像が本物か偽物かを判別する「判別器」が存在する仕組みを理解してください。
生成器はこれまで学習した画像(本物)の中からプロンプトに適した画像(偽物)を生成しています。この生成した画像を判別器が「本物か偽物か」を判断し、偽物であると判断されると生成器は判別器に本物だと判断させるように画像を作り直す工程に入ります。
生成器は「判別器に本物だと判断させる能力」、判別器は「偽物か本物かを見極める能力」を相互に磨き合うことによって最終的に本物の画像に近く、クオリティの高い画像が生成できるようになるわけです。
VAE(変分オートエンコーダ)
VAE(変分オートエンコーダ)とは生成モデルの1つで、ディープラーニングの技術を活用しています。
「生成モデル」とはデータを生成できるAIの一種で、画像生成AIの場合にはこの「データ」は「画像」を意味しているわけです。大量の訓練データから特徴やパターンを学習し、それを元に新しい画像を生成しています。
VAEもこの説明と同じく「画像の特徴抽出」と「再生」を繰り返す機能です。
「与えられた画像からさまざまな特徴を抽出し、その情報を元に画像を再現する」といった順序を自身で繰り返す事によって新しい画像を作る機能が利用できるようになります。
関連記事:ディープラーニングとは?仕組みから活用例までわかりやすく解説
Pix2Pix
Pix2Pixはすでにある画像から新しく画像を生成する技術です。
例えば学習データとして、白黒とカラー画像のペアを何百万枚も取り込むことによって、新しい白黒画像を見た時に「どのようなカラーに変換すれば良いのか」を理解できるようになります。
TransGAN
TransGANとは「Transformer」という技術を用いた画像生成AI技術です。Transformerは元々テキストを理解するために開発された技術で、単語や文章の「関連性」を理解する能力があります。
TransGANはこのTransformerを利用して、画像の各ピクセルに「どのような関連性があるのか」の全体像を理解することによって、クオリティの高い画像生成を可能にしています。
例えば「空と一本の木」を私たちが描く場合、空と木の位置関係やバランスは感覚的に分かりますよね。しかしAIは、私たちのように感覚的には物事を捉えられません。
TransGANは多くのデータから空や木といった部分部分の関連性などを学ぶことによって「空は上で、木はその下にある」というふうに理解ができるようになります。
DALL-E
DALL-Eは、ChatGPTを提供しているOpenAIが開発した画像生成AIの1つです。
DALL-Eは大量の学習データから特徴やパターンを読み取る能力が高いため、それを活かして現実には存在しない画像を生成できます。
例えば「顔がトラで体はキリン」という現実世界ではあり得ない画像を生成する場合を想定してみましょう。
DALL-Eはトラとキリンそれぞれの特徴とパターンを大量の学習データから学んでいるため、それらを組み合わせて実際に画像を生成することが可能です。
StyleGAN/StyleGAN2
StyleGANは、解像度の高い人間の画像を生成するために生まれました。この技術を使うことによって目の質感や髪の毛の雰囲気などより細部まで再現することが可能です。
StyleGAN2はその名前の通りStyleGANの進化版と思っていただければ大丈夫です。StyleGANでは、生成された人間の画像に歪みがあったり、色彩などの表現力が低いという問題点がありました。
StyleGAN2に改良されたことによって、そのような問題点が緩和され、より解像度の高い人間が生成できるようになったわけです。
画像生成AIの著作権上の問題点とは
先ほども解説したように、画像生成AIは大量の「学習」によって成り立っています。つまり、学習元となる画像データが大量に必要となります。
画像生成AIサービスは、自社が保有する画像だけで学習を行わず、ネット上の画像を無断で学習データとして活用してしまっている例も少なくありません。
著作権問題をクリアし、商用利用するためには以下の2つの基準をクリアする必要があります。
- 画像生成AI提供会社が、商用利用を許可している
- 画像生成AIに用いられた学習データに、他者の著作物が含まれていない
画像生成AIを提供している会社が「商用利用OK」と主張していたとしても、学習データに他者の著作物が含まれている場合は注意が必要です。
ここに関しては法律上の議論が分かれるところなので明言はできませんが、生成された画像が他者の著作物に類似しすぎている場合には著作権侵害となる可能性があります。
画像生成AIのおすすめサービスは7つ
ここでは、初心者でも使えるおすすめの画像生成AIを7つご紹介します。
- Stable Diffusion
- Midjourney
- AIイラストくん
- Canva AI
- DALL-E2
- Adobe Firefly
- Bing Image Creator
Stable Diffusion
Stable Diffusionは、画像生成AIの火付け役ともなったサービスなので、まずは一度使ってみることをおすすめします。
登録も不要かつ無料で利用できるため、ぜひ使ってみてください。ただ、プロンプトは英語が推奨されており、日本語だと精度が高くありません。
サイトにて、「Mt.Fuji」と「富士山」の2つで入力してみました。
まずは英語で入力したものを見てみましょう。

ちゃんと富士山が生成されていることが分かりますね。
次に日本語で「富士山」と入力した例をみてみましょう。

上2つに関しては富士山が生成されていますが、下2つは富士山とは言えない画像が出てきてしまっています。
このように英語が推奨されている画像生成AIでは、基本的に英語で入力した方が精度の高い画像を生成できる場合が多いです。
Midjourney
Midjourneyは、Stable Diffusionと同様に画像生成AIの先駆けとして登場したサービスです。他の画像生成AIと比べてもハイクオリティな画像が生成できるため、中級者〜上級者に人気です。
Midjourneyは、Webサイト上では利用できず、コミュニケーションアプリDiscord内で操作する仕組みとなっています。
現在は無料プランが停止されているため、利用するためには月額8ドル〜が必要になります。
プロンプトは英語のみで日本語は非対応なので、翻訳サービスを使いながら英語で入力しましょう。
まずは他の画像生成AIに触れてみて「もっと専門的に学びたい」と思った人はぜひ利用してみてください。
AIイラストくん
AIイラストくんは、LINE上で簡単に画像生成ができるサービスです。
これまでは招待制で利用できない人も多かったのですが、現在は誰でも利用できるようになっています。
無料では1日3回までしか生成できませんが、普段使っているLINEで利用できるのはメリットだと言えますよね。
「画像生成AIを試したことがない」という人はぜひ使ってみてください。
Canva AI
Canva AIは、デザイナーなら誰でも一度は触れたことがあるデザインツールCanvaが提供している画像生成AIです。
Canvaはプレゼン資料も作成でき、AIで作成した画像をそのままプレゼンに利用できるのは大きなメリットだと言えます。
無料でも利用でき、日本語の精度も比較的高いため、初心者の人でも利用しやすい画像生成AIです。
DALL-E2(ダリ ツー)
DALL-Eは、ChatGPT開発企業のOpenAIが提供している画像生成AIサービスです。
DALL-E2は無料でも利用できますが、無料の場合は回数制限が存在しています。有料でも使い放題になるわけではなく、15ドルあたり115クレジットが付与される仕組みです。そのクレジットを消費して画像を生成する必要があります。
DALL-E2は生成された画像の編集が可能な点が魅力的です。他の画像生成AIサービスは、作った画像を編集できない場合も少なくありません。一度作って終わりではなく、生成した上で調整して自分好みの形に完成させられるのはメリットですよね。
DALL-E2も日本語は未対応なので、英語でプロンプトを入力して利用するようにしましょう。
Adobe Firefly
Adobe Fireflyは、PhotoshopやIllustratorなどを提供しているAdobeが提供している画像生成AIです。
Adobe Firefly最大のメリットは、著作権の問題が完全にクリアしている点です。
画像生成AI自体もAdobeが開発している上に、学習データは自社の画像を利用しているため、著作権問題を心配する必要がありません。
現時点ではベータ版なので活用の範囲は限られますが、本格的に利用できるようになれば多くの企業が利用することは間違いないでしょう。
プロンプトは英語が推奨されていますが、操作自体は難しくもないため初心者でもおすすめです。
Bing Image Creator
Bing Image Creatorは、Microsoftが提供している画像生成AIサービスです。
無料かつ日本語も対応しているため、初心者の人でも利用しやすいと言えるでしょう。
また、Microsoft Edgeブラウザに統合されているため、普段Edgeを利用している人はストレスなく利用できるのもメリットだと言えます。
画像生成AIの仕組みを理解すれば脱初心者を目指せる
ChatGPTをはじめ、急速にAIの認知度が高まってきたこともあり「使ったことはあるけど仕組みは知らない」という人が本当に多いです。
もちろんAIに触れるだけでも価値はありますが、仕組みを理解する事によって練度も高くなると思います。
AIは仕組みがややこしく、公表されていない部分も多いため、すべてを理解するのは難しいですが少しずつでも理解していきましょう。









コメント